State of the AWS Iceberg Data Lake
October 21, 2025AWS have taken an increasingly open-arms approach to Iceberg. Now in late 2025, we have an Iceberg spec REST API with AWS Glue Data Catalog, Iceberg-backed S3 table buckets that released late last year, and in Athena we have a query engine that comes close to offering the full Iceberg spec feature set.
Let's get some definitions out the way. A Data Lake is somewhere to store data, in a way that's scalable and appropriate for analytics workloads. Apache Iceberg is a data format used to store data in a Data Lake. AWS is Amazon Web Services, that thing that breaks the internet occasionally but also provides services that can be used to operate a Data Lake.
For those who need a recap, here's how to make Modern Data Lake™ with 3 simple ingredients:
-
Some storage
-
Some compute, to get data into the storage (let's call it ingestion)
-
A catalog, to manage metadata
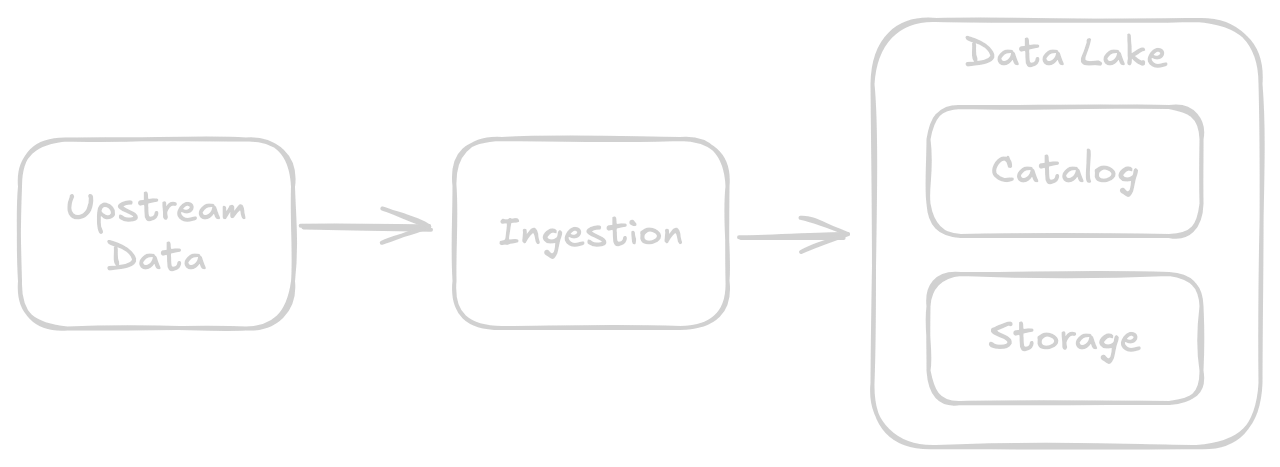
In our humble data pipeline here, upstream data gets read into an ingestion process, which handles conversion to the desired data format and manages the relationship with whatever catalog or metastore. Once data is in the Data Lake all the analytics workloads can take over, think dbt/SQLMesh, dashboards, AI/ML.
In AWS the default choice for a storage and catalog is S3 and Glue, respectively.
...